




Stel je voor dat je een spectrum van een onbekend molecuul scant en een paar suggesties krijgt van een AI-assistent over wat het zou kunnen zijn. Onderzoekers van MIT en IBM werken actief aan deze technologie en hebben al indrukwekkende resultaten behaald. ‘Wie AI niet omarmt, loopt het risico achterop te raken.’
Bij eenieder die analytische spectra voorgeschoteld krijgt, klinkt af en toe dezelfde bijna wanhopige vraag: ‘Wat zie ik hier in hemelsnaam?’ De recente ontwikkelingen op het gebied van AI, machinelearning en taalmodellen moedigen wetenschappers gelukkig aan om dit probleem met deze tools aan te pakken. Zo integreren nieuwe multimodale datasets verschillende spectroscopische gegevens, waardoor machinelearning-modellen moleculaire structuren nauwkeuriger kunnen voorspellen. Andere voorbeelden zijn modellen die infrarood- of massaspectra omzetten in molecuulstructuren.

Bij IBM werken distinguished research scientist Teodoro Laino en promovendus Marvin Alberts aan taalmodellen. ‘Ongeveer acht jaar geleden waren wij een van de eersten die dergelijke modellen voor wetenschappelijke taken inzetten’, zegt Laino, ‘en uiteindelijk leidde dat tot het oplossen van analytische spectra, waar Marvin aan werkt.’ Hun belangrijkste doel? Structuuropheldering. ‘Na een korte synthese tijdens mijn masteropleiding kostte het me meer dan een maand om alle benodigde metingen en karakteriseringen uit te voeren’, legt Alberts, die ook verbonden is aan de Universiteit van Zürich, uit. ‘Tijdens mijn doctoraat willen we dit proces automatiseren.’
IR-voorspellingen
Het begon allemaal met het voorspellen van chemische structuren op basis van IR-spectroscopie. ‘We hadden totaal geen garantie dat dit mogelijk was’, zegt Laino. ‘Maar Marvin heeft fantastisch werk geleverd en onlangs een voorspellingsnauwkeurigheid van 65 procent bereikt.’

Dat lijkt misschien niet zo denderend, maar het is behoorlijk indrukwekkend om in 65% van de gevallen het exacte molecuul te voorspellen op basis van alléén infraroodspectra, zegt Alberts. ‘Zelfs als de structuur door foutjes niet helemaal overeenkomt, ligt de voorspelde structuur vaak heel dicht bij de juiste.’
Tot nu toe had je relatief dure NMR-analyses nodig om de structuur van moleculen te bepalen. ‘Maar dankzij Marvins prestatie kun je nu een machine gebruiken die honderd keer goedkoper is’, zegt Laino. Dit kan een groot verschil maken in minder welvarende landen, omdat je in plaats van onbetaalbare NMR-apparatuur een draagbare infraroodspectroscoop kunt gebruiken in combinatie met AI-modellen.
790.000 moleculen
Toen bleek dat het voor IR werkte, probeerden ze het ook met NMR, maar daarvoor ontbrak het aan voldoende data voor training. Daarom besloten Alberts en Laino de basis te leggen voor een model dat automatische structuuropheldering kan doen. Daarvoor haalden ze moleculen uit reactiegegevens in octrooien die ze filterden op onder andere de molecuulstructuur . Vervolgens simuleerden ze de bijbehorende spectra voor elk molecuul, wat resulteerde in een dataset met spectra voor 790.000 moleculen.
Lees verder onder de afbeelding
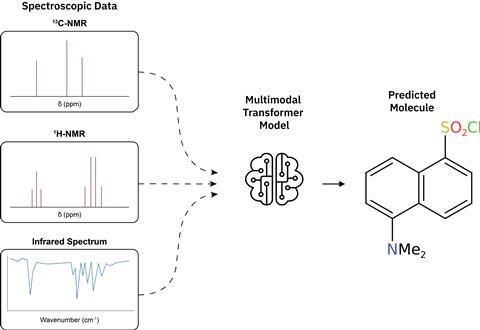
‘Met deze basis begonnen we met het trainen van de modellen’, vervolgt Laino. ‘De modellen presteerden goed en behaalden resultaten die vergelijkbaar waren met die van menselijke chemici, maar dan veel sneller. Zo losten ze één spectrum in slechts één seconde op.’ Door het model te gebruiken om suggesties te doen, kunnen chemici structuren veel sneller valideren en verifiëren, wat de efficiëntie ten goede komt.
Laino legt uit dat het op dezelfde manier werkt als een multimodaal taalmodel. ‘Denk aan bijschriften bij afbeeldingen.’ Deze modellen maken gebruik van contextuele kennis door input uit verschillende bronnen te bekijken. ‘Hetzelfde principe geldt voor ons model: we stellen het bloot aan verschillende soorten spectra en het gebruikt die informatie om een molecuulstructuur te reconstrueren.’ Ondanks de relatief kleine hoeveelheid gegevens die ze gebruikten, bereikte het team op deze manier een nauwkeurigheid van maar liefst 96%. ‘De moleculen zijn niet al te complex, maar het lijkt te wijzen op een toekomst waarin AI-modellen chemici echt kunnen helpen’, voegt Alberts toe.
MS-voorspellingen

Een ander initiatief uit de groep van associate professor Connor Coley aan MIT richt zich op massaspectrometrie (MS). Postdoc Runzhong Wang legt uit dat ze geïnspireerd zijn door het succes van AlphaFold. ‘We waren ervan overtuigd dat wij ook machinelearning-tools konden ontwikkelen om massaspectra op een vergelijkbare manier om te zetten in molecuulstructuren. Er is een redelijke hoeveelheid MS-gegevens beschikbaar, waardoor we deep learning-modellen konden ontwikkelen. We redeneerden dat er iets van een fysische wetmatigheid moest zijn die een brug kon slaan tussen moleculen en hun spectra.’
Montgomery Bohde, student aan de Texas A&M University die ook als onderzoeker bij Coley’s groep werkt, legt uit hoe hun model, DiffMS, werkt: ‘Het basisidee is in principe hetzelfde als dat van DALL-E, de beeldgenerator van ChatGPT.’ Eerst verzamel je je experimentele spectra en bepaal je de chemische formule. Deze kun je vervolgens invoeren in DiffMS, die een lijst met mogelijke structuren genereert.

‘We hebben het model bewust ontworpen met een generatieve aanpak waarbij je meerdere kandidaatstructuren krijgt’, vervolgt Bohde. ‘Het is erg moeilijk om de exacte structuur te voorspellen; het is makkelijker om vijftien opties aan te bieden, waarvan er één correct kan zijn. Dat is een nuttig resultaat. Bovendien kunnen meerdere moleculen vergelijkbare spectra hebben, denk aan leucine en isoleucine.’
Het project kostte Bohde ook nog eens wat extra moeite. ‘Als computerwetenschapper had ik helemaal geen ervaring met scheikunde of massaspectrometrie. Dat betekende dat ik vanaf nul met deze onderwerpen moest beginnen.’

Bedenkingen
Saer Samanipour, universitair hoofddocent aan de Universiteit van Amsterdam, die niet betrokken is bij de Coley- of IBM-groep, ziet veel nut in deze projecten. ‘Ik vind het deel over het combineren van spectroscopische gegevens erg goed en valide. Als je door een combinatie van technieken de structuur kunt achterhalen, gaat dat heel nuttig zijn – dat is de kracht van deze studies.’ Hij heeft echter ook enkele bedenkingen. ‘Ik denk dat het wat lastig zal zijn om met individuele technieken tot een structuur te komen.’
Samanipour vreest dat het gedeelte dat uitsluitend op massaspectrometriegegevens is gebaseerd, iets moeilijker te valideren zal zijn. ‘De Coley-groep gebruikte CFM-ID [een webtool die met ML massaspectra annoteert, red.], wat voor veel chemicaliën niet goed werkt, hoewel het momenteel de beste optie is. Het probleem met MS is dat er in de meeste gevallen onvoldoende gegevens zijn om het structuurprobleem op te lossen.’
Nauwkeurigheid
‘Het DiffMS-artikel was inderdaad een zeer uitdagend project’, zegt Wang. ‘Maar dankzij Montgomery waren we een van de eersten die met redelijke nauwkeurigheid structuren konden genereren op basis van een spectrum – ongeveer tien procent in plaats van één procent.’ Een ander project dat onlangs is gepubliceerd op Arxiv en BioRxiv heet ICEBERG. In plaats van een structuur te genereren op basis van een spectrum, doet dit model het omgekeerde: een spectrum genereren op basis van een structuur. De Coley-groep boekt al veelbelovende resultaten met deze methode.
Lees verder onder de afbeelding

Wang vervolgt: ‘Het ideaal waar we naartoe werken is het gebruik van machinelearning-modellen als een extra bewijs bij het matchen van structuren. Normaal gesproken moet je een ‘standaard’-molecuul kopen of synthetiseren om een referentiespectrum te genereren, en dat moet je voor elk kandidaat-molecuul in elk project doen.’ Hoewel het gebruik van iets als DiffMS of ICEBERG met hoge nauwkeurigheid misschien niet hetzelfde betrouwbaarheidsniveau oplevert als een echte standaard, gelooft Wang dat het een haalbaar, tijd- en kostenbesparend alternatief kan zijn.

Digitale toekomst
Laino gelooft dat de toekomst van de chemie digitaal zal zijn. Chemici zullen toegang hebben tot digitale tools zoals retrosyntheseontwerp en autonome laboratoria. ‘AI zal chemici niet vervangen, maar wie AI en alle daarmee verbonden technologieën niet omarmt, loopt het risico achterop te raken.’ Het vakgebied zal evolueren. Op welke manier? ‘In plaats van tijd te besteden aan het bekijken van spectra en het uitzoeken van de structuur, kun je gewoon op een knop drukken en binnen een seconde een paar suggesties krijgen.’
Samanipour denkt echter dat dit zou betekenen dat waardevolle kennis verloren gaat: ‘Het is altijd een kunst geweest om van een NMR- of MS-spectrum tot de structuur te komen. Het gaat niet alleen om het bekijken van de pieken, maar ook om kennis van de meetomgeving en hoe de analyse is uitgevoerd.’ Hij zegt dat er altijd een probleem is met het verlies van de kunst wanneer je automatische technieken gaat gebruiken. ‘Denk aan rekenen: we gebruiken onze telefoons om zelfs eenvoudige dingen uit te rekenen. De kunst van het uit je hoofd te doen is vrijwel verdwenen. Tegelijkertijd besparen we daardoor wel tijd of verhogen we de snelheid.’
‘We moeten studenten kennis laten maken met deze technologie en hen tegelijkertijd leren kritisch na te denken over het proces’
Teodoro Laino
Laino ziet het anders. ‘Ik ben een groot voorstander van het zo vroeg mogelijk introduceren van deze technieken in het onderwijs’, zegt de IBM-onderzoeker. Hij noemt schrijven als voorbeeld: dankzij AI-tools is het veel gemakkelijker geworden dan een paar jaar geleden. ‘We moeten studenten kennis laten maken met deze technologie en hen tegelijkertijd leren kritisch na te denken over het proces en hen de vaardigheden bijbrengen om de technologie te beoordelen.’
Alberts voegt hieraan toe: ‘Het model is nog niet onfeilbaar. De output moet je beschouwen als een suggestie die je moet beoordelen. Ik geloof niet dat we het vermogen om structuren te verklaren zullen verliezen. Het zal evolueren, maar chemici zullen nog steeds moeten begrijpen hoe spectra werken en hoe je ze moet interpreteren.’
Ruissignalen
Een terechte kritiek op dit werk is dat deze technologieën worden gebruikt om moleculen te genereren op basis van spectra van afzonderlijke verbindingen. ‘Zodra je een spectrum hebt dat een mengsel bevat, wordt het te ingewikkeld om het molecuul te ontcijferen, omdat ruissignalen je kunnen misleiden’, zegt Samanipour.
‘We zijn momenteel bezig met het ontwikkelen van een methode dat zich richt op mengsels’
Marvin Alberts
De teams hebben echter rekening gehouden met deze uitdaging. Wang: ‘Het is een goed punt! We gaan uit van een situatie waarin alle verbindingen zijn gescheiden door zowel vloeistofchromatografie als MS1 – dat wil zeggen verschillende precursor-massawaarden – zodat elk massaspectrum dat je bekijkt een enkele verbinding is.’ Natuurlijk is het mogelijk dat er verbindingen zijn die samen elueren, maar Wang gelooft dat er experimentele technieken in LC-MS/MS zijn die dergelijke problemen mogelijk kunnen oplossen.

Alberts is optimistisch over deze kwestie: ‘We zijn momenteel bezig met het ontwikkelen van een methode dat zich richt op mengsels. We willen structuren ophelderen van mengsels met behulp van IR-spectra, en we hebben al verrassend goede resultaten behaald. We bereiden dit werk voor publicatie voor en hebben zojuist een preprint uitgebracht.’
Ondanks zijn bedenkingen is Samanipour overtuigd van het potentieel van deze technieken. ‘Van eenvoudige synthetische chemie tot geneesmiddelenontwikkeling, analytische chemie, metabolomica en het exposoom: al deze vakgebieden houden zich bezig met het identificeren van onbekende stoffen. Ik ben er oprecht van overtuigd dat je databases als deze kunt inzetten om het lot en het gedrag van chemische stoffen te voorspellen, wat veel deuren zou openen voor een beter begrip van het exposoom. Het is goed dat dit openbaar en toegankelijk is en ik hoop dat we snel gebruik kunnen maken van deze datasets.’
‘Onze modellen losten één spectrum in slechts één seconde op’ – Teodoro Laino, IBM










1 Opmerking van een lezer