





Het zal nog wel even duren voordat computers zelfstandig chemische fabrieken kunnen ontwerpen. Maar meedenken met menselijke procestechnologen kan een AI inmiddels wel.
In eerste instantie studeerde Artur Schweidtmann werktuigbouwkunde. Maar tijdens een verblijf aan Carnegie Mellon University (VS), werd hij gegrepen door procestechnologie. Vervolgens schreef hij zijn masterscriptie in Cambridge (VK), waar ook zijn interesse in AI, artificial intelligence, werd gewekt. Zo maakte hij zich een bijzondere combinatie van vakdisciplines eigen, waarmee hij, na zijn promotie aan de RWTH in Aken, meteen kon beginnen als universitair docent aan de TU Delft. Sinds eind 2020 loopt daar een grootschalig AI Initiative, dat alle acht faculteiten bestrijkt en 24 nieuwe AI-labs moet opleveren met budget voor 48 tenure trackers en 96 promovendi. ‛They’re hiring like crazy’, zo vat Schweidtmann het samen. Inmiddels is hij voldoende ingewerkt om ‘like crazy’ te publiceren. Deze zomer verschenen binnen één week drie preprints op arXiv. Samen geven zij een aardig beeld van zijn ideeën voor de toekomst.
Little & Perry
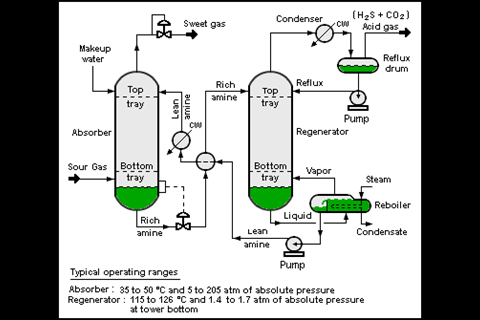
Om die ideeën te begrijpen, moet je weten dat de klassieke chemische technologie is gebaseerd op zogeheten unit operations. Die term is in 1916 gemunt door Arthur D. Little, oprichter van het gelijknamige adviesbureau, maar is vooral bekend dankzij Perry’s Chemical Engineering Handbook. Deze ‘technologenbijbel’ stamt uit 1934 en er verschijnen nog steeds herziene drukken, voor het laatst in 2018. Volgens Perry is elke reactor, destillatiekolom, warmtewisselaar, pomp of ander apparaat een unit operation; een bouwsteen voor een chemische fabriek. De truc is dat je al die bouwstenen apart ontwerpt, waarbij naburige unit operations enkel de randvoorwaarden bepalen. Zo’n opsplitsing in hapklare brokken vereenvoudigt het rekenwerk enorm en als je je papieren ontwerp vertaalt naar roestvast staal, weet je bijna zeker dat het resultaat correct zal functioneren. Ook zonder computersimulaties. De huidige chemische industrie stamt immers grotendeels uit de tijd dat die er nog niet waren.
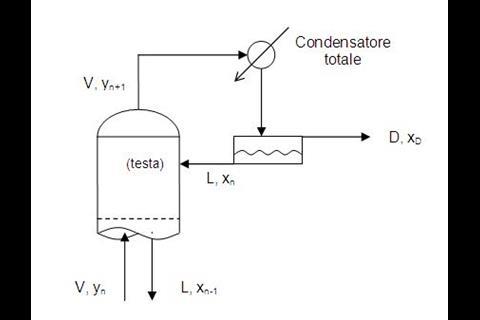
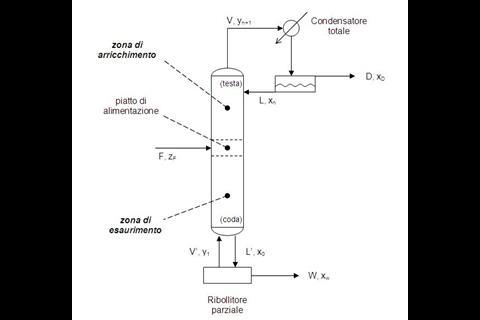
In eerste instantie wordt zo’n basisontwerp vastgelegd in een flowsheet. Elk onderdeel is daarin weergegeven als een symbool, met verbindende lijntjes die de leidingen voorstellen. Die symbolen, die alleen het type unit operation aangeven en niet de constructieve details, zijn al vele tientallen jaren gestandaardiseerd. En dat is essentieel voor Schweidtmanns benadering. Die begint namelijk met een algoritme dat zo’n flowsheet scant en vertaalt naar strings; reeksen lettertekens die als invoer dienen voor bestaande algoritmes uit de wereld van AI en machine learning.
‘Je kunt een molecuul ook zien als een proces’
De gebruikte computertaal, SFILES (simplified flowsheet input-line entry-system) is gebaseerd op SMILES, met de M van molecules. Die taal zet structuurformules om in een formaat dat geschikt is voor zoekmachines. Het verschil is niet eens zo groot, vindt Schweidtmann: ‛Je kunt een molecuul zien als een proces, met de atomen als unit operations en de bindingen als leidingen. Het verschil is dat de stromen in een proces maar één kant op gaan.’
SFILES 2.0, door zijn groep zojuist op arXiv gezet, kan het overgrote deel van de huidige flowsheets aan. Volgens Schweidtmann kan de chemische industrie hiermee eindelijk haar tekeningenarchieven digitaliseren. Naast de flowsheets zijn dat ook de piping and instrumentation diagrams (P&ID) die erop lijken, maar ook de belangrijkste afsluiters en meetpunten aangeven en meer details bevatten over de feitelijke constructie van de fabriek. ‘Die zijn vaak nog met de hand getekend, of met een verouderd softwarepakket. Eens in de zoveel jaar moest men ze hertekenen, of bijwerken met pen en inkt, als er iets aan de fabriek was gewijzigd. Misschien hebben ze inmiddels ook 3D-modellen, maar dat is wéér andere software. Al die databestanden staan los van elkaar en je kunt lastig zien welke unit operation op de flowsheet overeenkomt met welk fabrieksonderdeel. In de toekomst zou dat door digitalisering geen probleem meer moeten zijn.’

Witte plekken
Zelf ziet Schweidtmann deze digitaliseringsslag als opstapje om AI serieus aan het ontwerpen van processen te zetten. Eerst door ze de witte plekken in flowsheets automatisch te laten invullen, net zoals Google dat doet bij zoekopdrachten. Een manier om de productiviteit te verhogen, zo ziet hij het. Niet om blind op te varen, maar om de menselijke procestechnoloog sneller naar een werkbare oplossing te loodsen.
Dit werkt met reinforced learning, zo legt hij uit. Bij die vorm van machine learning laat de AI kosten-batenanalyses los op een aantal mogelijke probleemoplossingen, en kiest dan de optie die de meeste virtuele euro’s oplevert. Het principe is populair binnen de gaming-wereld; Google-dochter DeepMind wist zo onder meer de wereldkampioen Go te verslaan. In de arXiv-publicatie dient de verestering van azijnzuur tot methylacetaat als praktisch voorbeeld. Een simpel proces waar toch nog wel wat alternatieven voor valt te verzinnen.
‘De AI kan data combineren op een manier waar wij nooit aan zouden denken’
Om de AI te trainen heb je altijd bestaande datasets nodig. In dit geval dus in de praktijk geverifieerde flowsheets en P&ID’s. Het overgrote deel daarvan ligt helaas achter slot en grendel bij chemieconcerns en ingenieursbureaus, dat ze koesteren als bedrijfsgeheim. Maar uit openbare publicaties en octrooien valt volgens Schweidtmann voldoende materiaal te halen om te demonstreren dat het idee werkt. Zijn groep heeft daar weer een ander algoritme voor ontwikkeld dat aan data mining doet: het ploegt de literatuur door, herkent illustraties die de kenmerken vertonen van flowsheets of P&ID’s, en speelt die door aan het eerdergenoemde algoritme dat er SFILES-vertalingen van maakt.
‘In wezen maken we zo een database van alle flowsheets ter wereld’, zegt Schweidtmann. Alles wordt opgeslagen volgens de zogeheten FAIR-maatstaven (findability, accessibility, interoperability, reusability) zodat anderen er ook iets mee kunnen. Ook zit er een zoekfunctie in waarmee je bijvoorbeeld mogelijkheden kunt vinden om afvalstroom A om te zetten in product B. ‘Er zitten nu een paar duizend schema’s in, en ik denk dat we tot enkele honderdduizenden kunnen komen.’
Verrassing?
Loop je niet het risico dat de AI net zulke domme fouten maakt als Google soms doet? ‘Meestal krijg ik precies het omgekeerde commentaar’, stelt Schweidtmann. ‘Zo van: zolang je je baseert op bestaande data, zal er nooit iets verrassends uit komen. Maar de AI kan data wél combineren op een manier waar wij nooit aan zouden denken. En het klopt dat de AI nu nog maar een beperkt aantal unit operations kent en nieuwe ontwikkelingen, die nog niet in de collectie zitten, nooit ergens zal inplannen. Maar het is ook nog maar een prototype, dat verder moet worden uitgewerkt.’
Het idee hoeft zich ook niet te beperken tot unit operations. Sinds begin jaren ‘90 ligt dat ontwerpprincipe onder vuur omdat het energieverspilling in de hand werkt. De schade is achteraf te beperken met warmtewisselaars die overtollige hitte uit het ene onderdeel benutten om elders in het proces iets op te warmen. Maar ongetwijfeld kun je bij nieuwbouw meer besparen door die onderdelen vanaf het begin te integreren. Volgens Schweidtmann kun je daaraan tegemoetkomen door acties anders te definiëren. ’Niet zeggen: hier moet een unit operation komen, maar: hier moet iets worden opgewarmd of hier moet iets reageren. En zo een flowsheet opbouwen op basis van wat er eigenlijk in de unit operations gebeurt.’
Menselijke kennis
Niet alleen Schweidtmann zet algoritmes in bij procesontwerp. Het Process Design Center (PDC) in Breda is er al tientallen jaren mee bezig, vertelt chief technology officer Hank Vleeming. Een expertsysteem genaamd PROSYN, ooit in Dortmund ontstaan en in Breda verder uitgewerkt, speelt daarbij een centrale rol. ‘Naast numerieke methoden maakt het gebruik van chemisch-technologische regels, gebaseerd op kennis van experts in het veld’, legt Vleeming uit. Hij schat dat er al meer dan 300 mensjaar is gaan zitten in het invoeren en verfijnen van die regels. ’Het systeem gebruikt ze om op basis van kwantitatieve en kwalitatieve informatie over de aanwezige componenten en de reacties die plaatsvinden, verschillende alternatieven te evalueren en te beoordelen op geschiktheid. Deze worden vervolgens geïntegreerd in een geoptimaliseerde flowsheet.’ PDC claimt dat het mede dankzij PROSYN de kapitaal- en energiekosten van sommige bestaande processen kan terugbrengen met 20 tot 50%.
‘We maken een database van alle flowsheets ter wereld’
Vleeming memoreert dat de ontwikkeling van gestructureerd procesontwerp eind jaren ’60 al is begonnen, en daarna dankzij de opkomst van de computer in een stroomversnelling raakte. Duitse universiteiten en bedrijven concentreerden zich daarbij op de ontwikkeling van algemene kennisregels, ook wel heuristieken genoemd. De Amerikaanse school, met Carnegie Mellon als zwaartepunt, richtte zich meer op zogeheten superstructuren waarin alle mogelijke alternatieve unit operations waren opgenomen, zodat het vinden van de ideale oplossing een kwestie werd van wiskunde.
In Schweidtmanns aanpak ziet Vleeming elementen van beide stromingen: ’De representatie in flowsheet-vorm met ongedefinieerde knopen, de nodes, van waaruit het procesontwerp verder gaat, wordt ook gebruikt in PROSYN. De evaluatie van alternatieve bouwstenen en het al dan niet toevoegen hiervan in een flowsheet zie je ook terug bij het oplossen van superstructuren. Het interessante is machine learning als nieuw element. Dankzij reinforced learning en de gekozen optimalisatie-aanpak wordt flexibiliteit toegevoegd en vervalt de noodzaak voor een superstructuur. Op deze manier kun je een breder scala aan ingenieus samengeknoopte alternatieve flowsheets scannen.’
‘Dat een geautomatiseerd procesontwerp echte doorbraken realiseert, is een utopische gedachte’
Routeplanner
Vleeming en collega’s zien nog wel uitdagingen voor de AI. ‘Specifieke data, zoals de kinetiek van een bepaalde reactie, zijn vaak niet voorhanden of alleen beschikbaar in kwalitatieve vorm. Ook zijn er ontwerpaspecten, die meer op ervaring zijn gebaseerd en zich lastig in modellen of data laten vastleggen. Blijven componenten stabiel en treedt er geen vervuiling op? Zitten arbitraire grenzen, die de gebruiker heeft opgegeven, niet angstig dicht tegen het punt waarbij ongewenste nevenreacties de kop gaan opsteken? En wat als je kiest voor een oplossingsrichting die in de praktijk gewoon niet blijkt te werken? Dit soort problemen zijn algemeen in procesontwerp. Een systeem als dat van Schweidtmann kan de gebruiker misschien helpen hiertegen te vechten, bijvoorbeeld door toe te laten dat je kiest voor een net wat minder optimaal geachte oplossing. Net zoals routeplanners in auto’s doen.’
In Breda zien ze een AI dan ook nog niet zelfstandig tot een optimaal ontwerp komen. ‘We mogen geen wonderen verwachten van de nieuwe aanpak’, stelt Vleeming. ‘De praktijk van meer dan dertig jaar industrieel procesontwerp heeft ons geleerd dat - uitzonderingen daargelaten - voor het realiseren van echte doorbraken een geautomatiseerd procesontwerp een utopische gedachte is. Zeker wanneer je vanuit R&D-resultaten een nieuw proces probeert te ontwikkelen. Het is zonde als zo’n poging bij de eerste evaluatie sneuvelt wanneer een ervaren procestechnoloog meteen ziet dat het niet zal werken. Om tot een significant beter resultaat te komen dan met de conventionele manier van procesontwerp, kun je in onze ervaring het beste werken met een combinatie van technieken, ondersteund door een ontwerpteam waarin verschillende disciplines vertegenwoordigd zijn. Het AI-algoritme van Schweidtmann kan daarbij een mooie nieuwe kans bieden waar we graag aan bijdragen.’










Nog geen opmerkingen